
Speech-to-Retrieval, Google Unveils a New Approach to Voice Search

Among artificial intelligence models and advanced voice assistants, search is also evolving with a new approach coined by Google as Speech-to-Retrieval: the announcement comes from a blog post published by Ehsan Variani and Michael Riley, scientific researchers at Google Research.
Today's common voice search technologies are focused on the question, "What words were said?" What if we could answer a more powerful question: "What information is being sought?" Introducing the new Speech-to-Retrieval (S2R) model in today's blog → https://t.co/eDL0JM0GRV pic.twitter.com/Eg2xILbPWW
— Google Research (@GoogleResearch) October 7, 2025
Having been available for years, searching for information on the web by voice continues to be used by many people today. However, while Google's initial voice search technology relied on automatic speech recognition (ASR), which transformed audio input into a text query and then searched for matching documents, it has been proven that even the smallest errors in speech recognition can alter the meaning of the query and return incorrect results. The researchers explain in the article how a voice search can yield incorrect results, providing a concrete example: a user utters the query "the Scream painting" with the intent of obtaining information on Edvard Munch's famous work. However, if the ASR system swaps the "m" for "n," the query is transcribed as "screen painting," thus providing results related to painting techniques rather than the artist's masterpiece. In this regard, the new Speech-to-Retrieval (S2R) engine is effective, capable of interpreting and recovering information from a vocal query without carrying out the intermediate step of text transcription, which is susceptible to artifacts: in fact, if the most common voice search technologies are based on the question "What words were pronounced", the S2R model answers the question "What information are you looking for?".
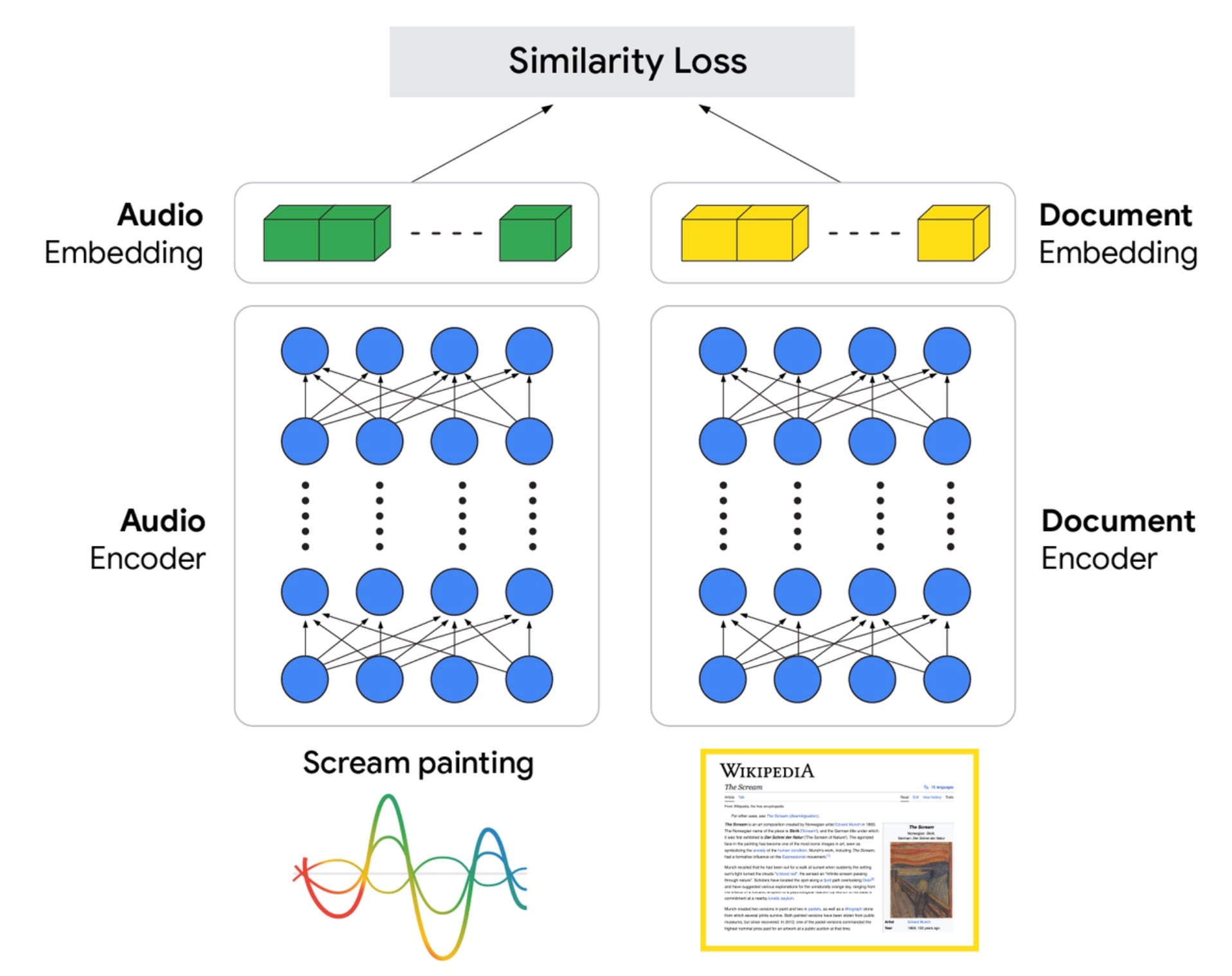
The announced model is based on a dual-encoder architecture that includes two neural networks that learn from massive amounts of data to understand the relationships between what the user says and the available information: one encoder processes the audio, converting it into a vector representation from which it captures the semantic meaning, while a second encoder develops a vector representation for documents. In other words, when a user utters a voice search query, the audio is streamed to an encoder, a pre-trained model capable of transforming sounds into data. This process creates a sort of digital fingerprint that captures the deeper meaning of the query and is then used to identify a set of relevant results through a search ranking process. Of course, this is only the first step, as the final result is still managed by the ranking system, which interweaves hundreds of useful signals to understand relevance, quality, and other information to compile the final list of results that are more useful and closer to the user's search intent.
In conclusion, S2R-based voice search is not just an academic experiment but a fully operational evolution. Indeed, thanks to the close collaboration between the Google Research and Search teams, these next-generation models are now implemented in multiple languages, offering significant improvements in accuracy and latency compared to traditional systems. Furthermore, to support the advancement of research in this field, Google has decided to open source the Spoken Query Dataset (SVQ) as part of the Massive Sound Embedding Benchmark (MSEB). By sharing these resources, the Mountain View company intends to encourage the global scientific community to experiment, compare models, and contribute to the creation of the next generation of intelligent voice interfaces, capable of understanding and responding naturally to the nuances of human language.
ilsole24ore




